


Addressing Face Verification Limitations from an African Perspective
Introduction
Face verification technology is a key tool with broad ramifications in the ever-evolving world of technology, especially in the fintech and banking sectors. The use cases of face verification range from protecting online transactions to helping businesses know their customers. However, as we examine the nuances of face verification, it becomes clear that there are particular difficulties that need to be addressed, especially from an African standpoint. In this blog post, we explore these issues with the goal of shedding light on the intricacies of face verification AI models and highlighting the need for AI models that are specifically adapted to the varied African setting.
Understanding Face Verification
Face verification is a fundamental task in the domain of computer vision, in which an automated system determines the likeness between two facial images with utmost precision. This intricate process happens in stages, commencing with a face detection model first locating faces within images. Subsequently, a face recognition model comes into play to extract distinctive features from these faces. And finally, a distance metric is then used to compare these features to determine whether or not the faces belong to the same person.
The significance of face verification extends across diverse industries. It is commonly used in enhancing security systems, like smartphone unlocking or gaining access to a secure facility, to a wide array of contexts where verifying a person’s identity through their facial image is imperative.
Facial Verification Challenges and the African Perspective
Despite their widespread applications, facial verification systems struggle with an alarming issue: racial discrimination. The implications of this issue are particularly pronounced when considering facial verification AI models in the African context. A comprehensive analysis of the available data reveals a stark disparity in the accuracy of these systems when confronted with different skin tones.
According to a 2018 report, when dealing with lighter skin tones, facial recognition algorithms meet an incredible 99% accuracy rate. When asked to recognize the faces of people with darker skin tone, this accuracy dropped to a dismal 35%. The disparity in these figures is a strong sign of a deeper issue within these AI systems.
The problems persist beyond these numerical differences. Extensive research undertaken in 2018 by groups such as the American Civil Liberties Union (ACLU) and the Massachusetts Institute of Technology (MIT) emphasized the racial biases found in facial recognition algorithms. Microsoft, Amazon, and IBM were discovered to have algorithms with much worse accuracy rates when analyzing photographs of people with darker skin tones.
These findings indisputably demonstrate the significant racial discrepancies and limitations in current facial recognition AI models. As a result, it is evident that these models are unsuitable for the African setting, where a broad range of skin tones and face features necessitate a higher level of accuracy and inclusivity. Addressing these limits is a moral as well as a technological necessity, as it ensures that AI-driven facial verification systems serve all members of society equitably and without bias. In the subsequent sections, we share our approach for resolving these difficulties and creating AI models that are both equitable and effective in the African environment.
Our Approach: Methods of Face Verification
To establish a reliable face verification system, it's essential to follow a well-defined pipeline. A good pipeline involves passing two images intended for verification, first through a face detection model, such as OpenCV or Google Cloud Vision. Subsequently, the result is then passed through a model capable of representing the images as embeddings, such as the VGG Face Model or Facebook’s Deep Lab. Finally, a distance metric, like the cosine distance metric, would be used to assess the similarity between these images. If the value of the distance falls below a certain predefined metric, the images are considered similar; otherwise, they are deemed different. A visual representation of this entire process is illustrated in Figure 1 below.
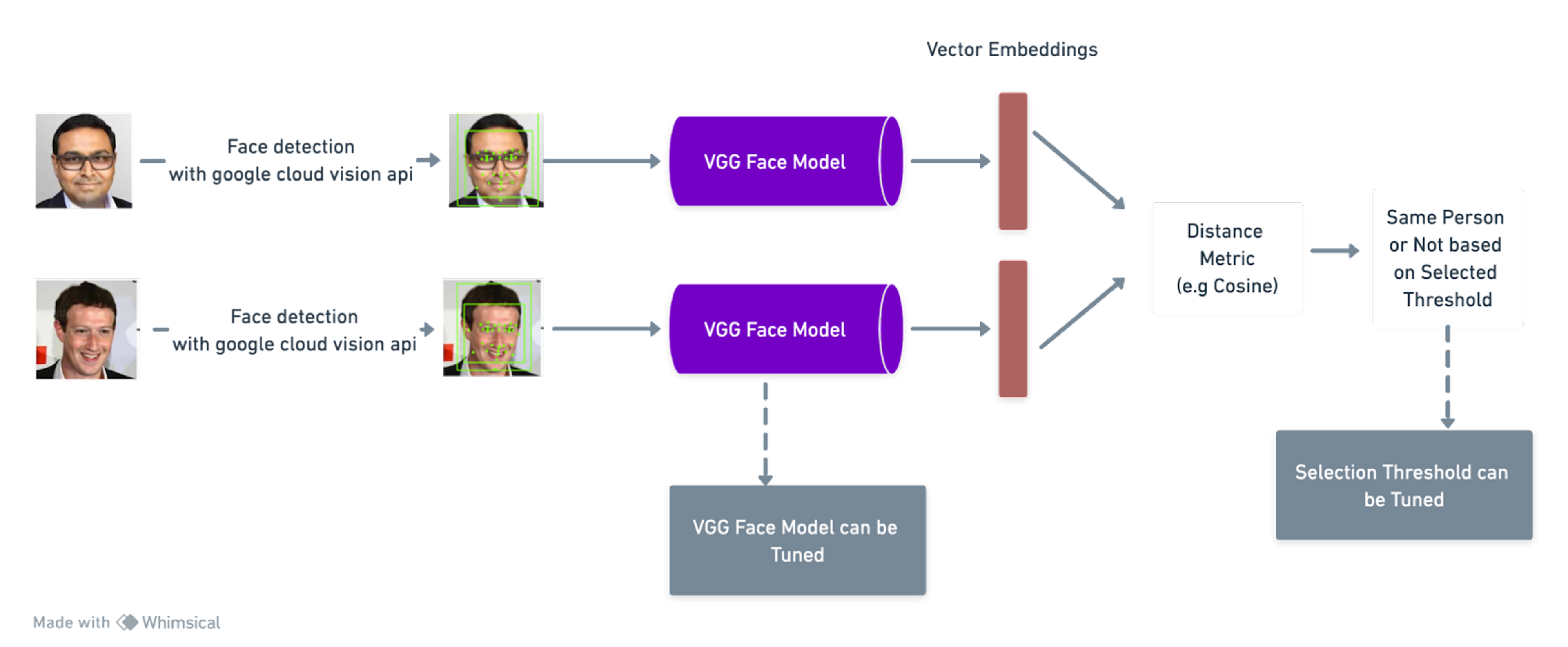
Fig1: Face Verification Pipeline
In our pursuit of an effective face verification model, we explored a state-of-the-art solution known as the deep face model for facial verification. Instead of building a model from scratch, we opted to utilize an existing, pre-trained model to make predictions. However, it's worth noting that the initial result might not be very standard. This disparity arises from differences between the distribution of the data used in our context and the distribution of the data the model was originally trained on. The bias in facial recognition emerges primarily from this difference in data distribution, as the embeddings created during training inadequately represent African faces. To significantly improve performance, we adopted a process known as fine-tuning.
Our fine-tuning process consisted of two key methods:
1. Fine-tune the Threshold
2. Fine-tune the Face Model itself
Fine-Tuning the Threshold
Selecting an appropriate threshold to determine between similar and dissimilar images is a critical aspect of fine-tuning. This approach involves subjecting a set of similar and dissimilar faces through the pipeline. Subsequently, the distribution of positive and negative distances are then plotted to inspect the best distance value at which matching faces and non-matching faces can be discriminated. The objective was to identify the optimal threshold value at which matching and non-matching faces could be accurately discriminated. Ideally, in the instance where a discrimination exists, the distribution plot should resemble the image shown in Figure 2 below. The combination of visualization and a statistical approach is designed to aid in selecting the most suitable discrimination threshold, and also help with ensuring that the model is effective enough.
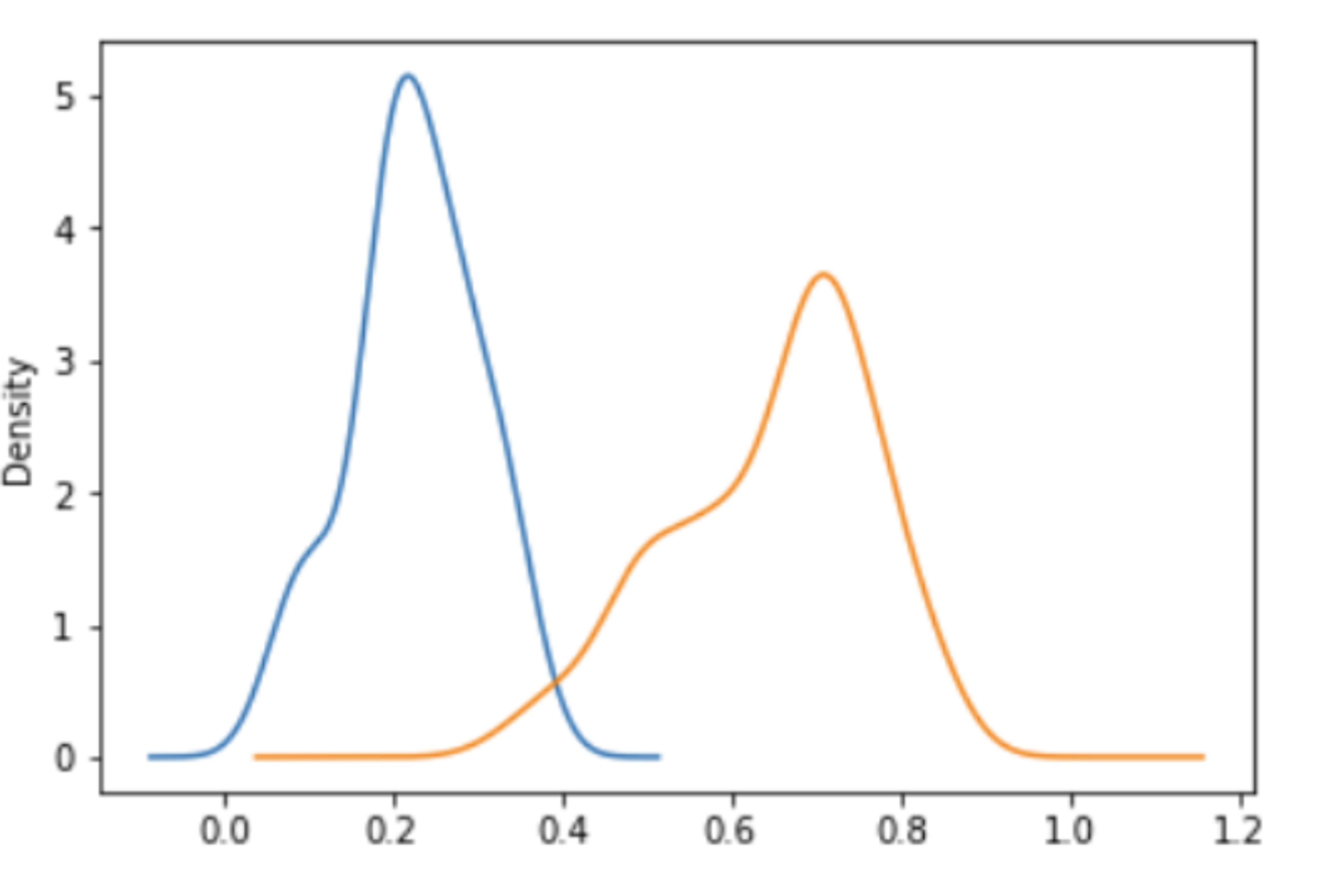
Figure 2: Distribution of threshold for matching and non-matching images.
Figure 2 depicts the result if the discrimination is not good. We can therefore observe from the visualization that choosing a threshold is difficult because the discrimination between matching and non-matching faces is poor. In such cases, several approaches can be explored, including statistical methods, machine learning models, or visual cues to select a threshold. For example, as seen in Figure 2, a threshold value of 0.4 may be considered suitable.
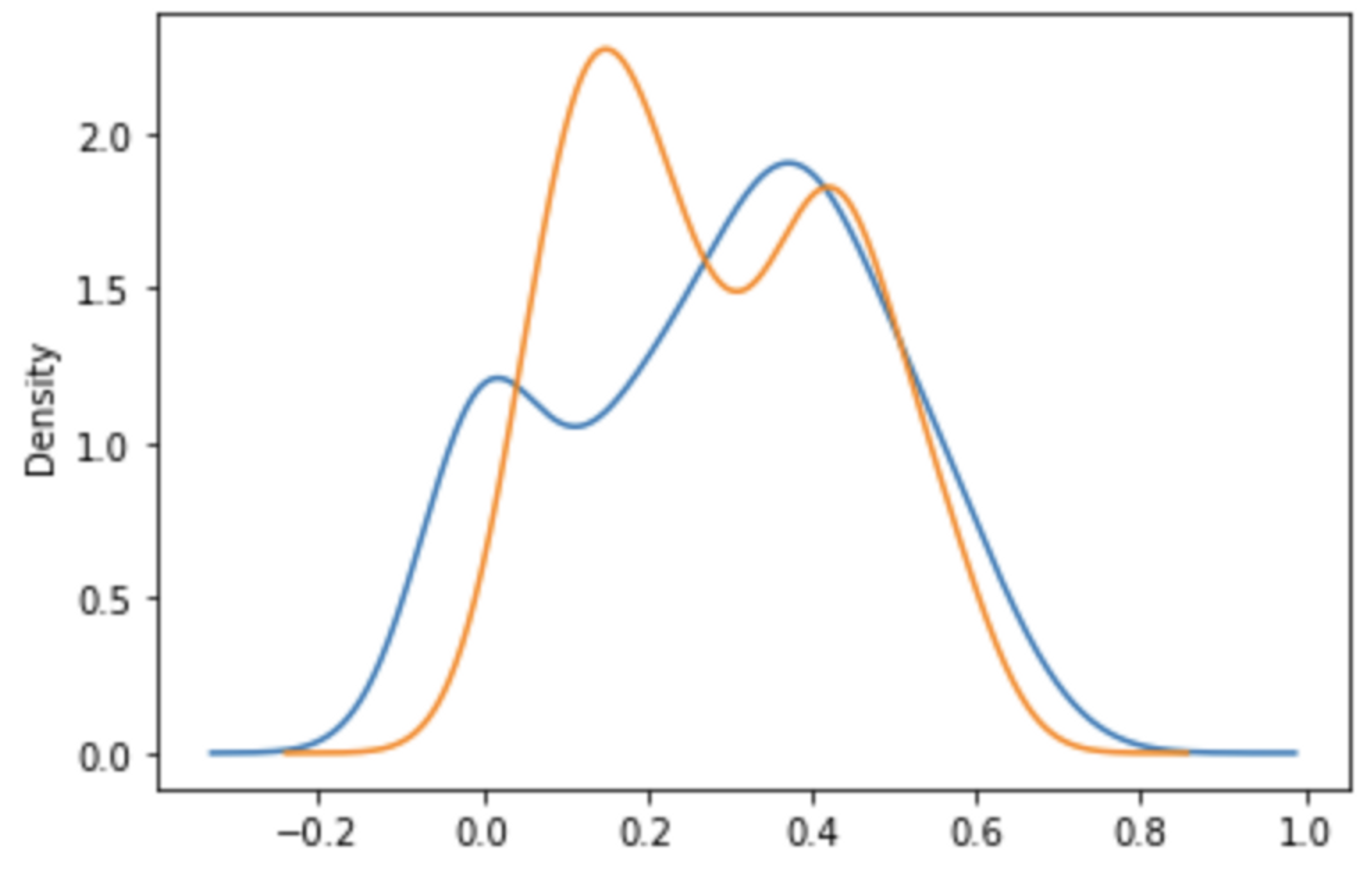
Figure 3: Distribution of threshold for matching and non-matching images for our initial deployment.
Fine-Tuning the Face Model
This method involves training the base model itself, such as VGG Face, through a method known as transfer learning. This method is done by hooking another classification model that takes the output of the face model and tries to classify the output embedding as belonging to the same person or not, using a technique called triplet loss. This method proves particularly useful when the initial threshold fine-tuning doesn't yield the desired results.
Triplet loss is a loss function used in deep learning, in the context of face recognition problems, where the task is to verify whether two images contain the same person or not. The goal of triplet loss is to learn a feature embedding space, where the distance between embeddings of two images of the same person is minimized, and the distance between embeddings of two images of different persons is maximized. Triplet loss operates based on the concept of triplets, consisting of an anchor image, a positive image (depicting the same person as the anchor), and a negative image (featuring a different person from the anchor). The loss function is based on the distances between the anchor and the positive image, as well as the anchor and the negative image. The method ensures that the distance between the anchor and the positive image is minimized, while the distance between the anchor and the negative image is maximized. This allows for the feature embedding space to be well separated in a way that images of the same person are kept close to each other, while images of different individuals are kept far apart.
The key to this process is to use a pre-trained VGG Face model and then freeze all layers except the final few layers and subsequently to train the model. The final model is then used for extracting embeddings as seen in Figure 1. This specific technique falls under the umbrella of transfer learning.
Transfer learning is a technique used in machine learning which entails reusing a model initially trained for one task as a starting point for a second task. This approach can be particularly advantageous when the second task lacks sufficient available data as the first task, allowing the pre-trained model to be fine-tuned with the available dataset to improve performance on the new task. In the context of Face Verification Model Fine Tuning, transfer learning is utilized to train the base model, such as VGG Face, by hooking another classification model that takes the output of the face model then tries to classify the embedding as belonging to the same person or not using the triplet loss technique. The base model is pre-trained on a large dataset and then fine-tuned on a smaller dataset of faces to optimize the performance of the face verification model.
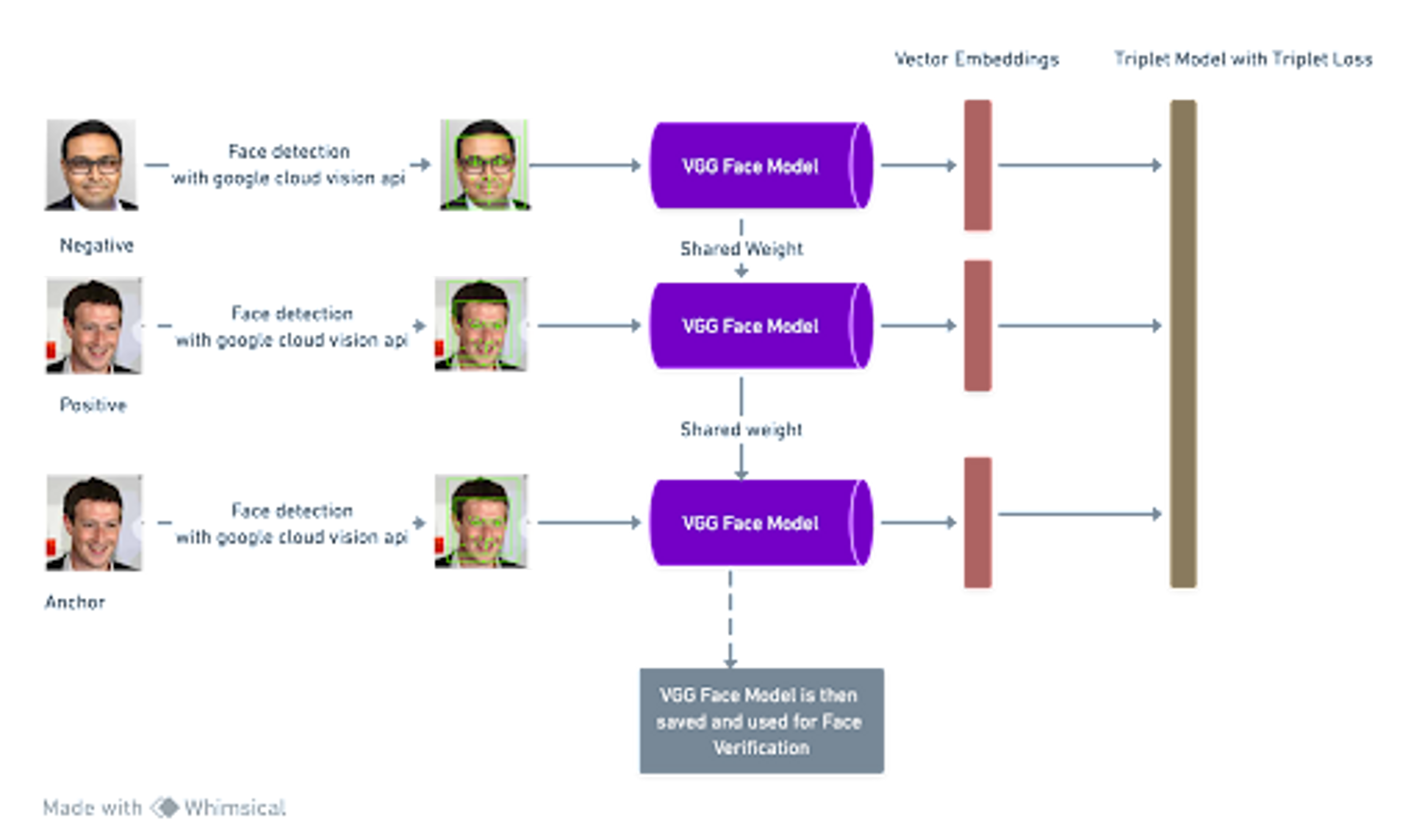
Figure 4: Pipeline for tuning face model.
The Way Forward: Adopting AI Models Trained for Africa
In light of the undeniable disparities and challenges faced by facial verification AI models in recognizing African faces, it is imperative that African enterprises shift focus towards adopting AI models meticulously trained for the African context. These customized models—which are sensitive to the range of skin tones and facial features throughout the continent—have the potential to close the accuracy and inclusivity gap in the application of face verification systems.
We can ensure that the benefits of facial verification are fairly distributed to all members of society by harnessing the power of AI specifically trained to consider the unique African context. This is a critical step in enhancing security systems, financial services, user experience, and other applications where identity verification is essential.
At Pastel, we are committed to pioneering solutions that address the specific needs of the African continent, and this extends to the realm of AI-driven facial verification. We invite you to stay tuned for more insightful blog posts, where we delve deeper into the transformative applications of AI in Africa.

